
type
status
date
slug
summary
tags
category
icon
password
原文:[[2203.14542v4] UNICON: Combating Label Noise Through Uniform Selection and Contrastive Learning (arxiv.org)]
摘要
有监督的深度学习方法需要大量的注释数据的检索。因此,标签噪声是不可避免的。使用这样的噪声数据进行训练会对深度神经网络的泛化性能产生负面影响。为了对抗标签噪声,最近最先进的方法采用了某种样本选择机制来选择一个可能干净的数据子集。接下来,使用一种现成的半监督学习方法进行训练,其中被拒绝的样本被视为未标记的数据。我们的综合分析表明,目前的选择方法不成比例地从简单的(快速可学习的)类中选择样本,而拒绝从相对较难的类中选择样本。这将在所选的干净集中造成类不平衡,进而在高标签噪声下恶化性能。在这项工作中,我们提出了UNICON,一种简单而有效的样本选择方法,它对高标签噪声具有鲁棒性。为了解决简单样本和困难样本的不成比例选择问题,我们引入了一种基于Jensen-Shannon divergence的均匀选择机制,该机制不需要任何概率建模和超参数调优。我们用对比学习来补充我们的选择方法,以进一步对抗对有噪声的标签的记忆。在多个基准数据集上的大量实验证明了UNICON的有效性;我们获得了11.4%的改善,超过目前最先进的CIFAR100数据集,噪声率为90%。代码是公开的nazmul-karim170/UNICON-Noisy-Label: Official Implementation of the CVPR 2022 paper “UNICON: Combating Label Noise Through Uniform Selection and Contrastive Learning” (github.com)
介绍
深度神经网络(DNNs)已被证明是解决各种计算机视觉任务的高效方法。大多数最先进的(SOTA)方法都需要使用大量的注释数据进行监督训练。收集和手动注释这样的数据具有挑战性,而且通常代价很高。大多数大规模的数据收集技术都依赖于开源的web数据,它可以通过搜索引擎查询和用户标签自动标注。这种标注方案不可避免地会引入标签噪声。使用这种有噪声的标签进行训练是具有挑战性的,因为DNN可以在训练过程中有效地记忆任意(有噪声的)标签。对抗标签噪声是深度学习中的基本问题之一,这也是本研究的重点。使用有噪声的标签数据进行训练一直是最近许多研究的主题。现有的技术技术可以分为两大类:i)标签校正,和ii)样品分离。前一种方法需要估计噪声的过渡矩阵,这在高数量的类和高噪声的情况下很难估计。后一种方法试图基于小损失准则从干净的样本中滤除有噪声的样本。其中,假设低损失的样品有干净的标签。接下来,使用一种现成的半监督学习(SSL)技术进行训练,其中选择的噪声样本被视为未标记的数据。然而,选择过程通常偏向于简单的类别,因为来自困难类别的干净样本(例如CIFAR中的猫和狗在CIFAR10[21]中可以被视为困难类别)可能会产生高损失值。然而,选择过程通常倾向于简单类作为困难类的干净样本。这在训练的早期阶段更为突出,并可能在所选择的干净样本之间引入类别差异。严重的类别不平衡可能导致样本选择的精度较差,从而导致分类性能不佳。在这项工作中,我们从一个更基本的角度修改了选择过程。我们的目标是通过引入一种有效的、可扩展的基于詹森-香农发散的样本分离机制来简化选择过程。为了解决简单样本和困难样本的不成比例的选择,我们通过从每个类中选择相同数量的干净样本来强制执行类平衡。这种先验提高了伪标签的整体质量,从而显著提高了后续的基于半监督学习的训练的性能。此外,我们选择使用无监督对比学习(CL),因为它固有的阻力(因为训练不需要标签)来标记噪声记忆。实验结果表明,无监督特征学习降低了记忆风险,提高了样本分离性能;特别是在严重的噪音水平下。我们称这种结合UNIform选择和协同学习UNICON的组合技术(如图1所示),我们发现即使在存在非常高的标签噪声的情况下也是有效的(见表1)。 我们的贡献总结如下:
- 我们提出了一种简单而有效的均匀选择机制,以确保所选的干净样本之间的类平衡。通过实证分析,我们观察到类别均匀性有助于为来自所有类别的样本生成更高质量的伪标签,而不管其难度水平如何。
- 我们通过使用对比损失进行无监督特征学习,从而进一步最小化标签噪声记忆的风险。这反过来又提高了样品的分离的性能。
- 我们广泛的实验表明,UNICON比最先进的方法取得了显著提升
背景
设表示训练集,其中是一张图片,y_i是相应的真实标签,N是总训练样本数。我们用一个特征提取器来实例化DNN模型。一个分类层,和一个全连接层(Projection Head)g(.;\psi),采用参数ψ来合并对比学习。对于使用真实标签的监督训练,我们在整个训练集上最小化cross-entropy loss 其中 是与对应的网络预测的softmax概率得分。 在这项工作中,我们认为训练集是有噪声的,即一些图像被错误地标记。已证明,DNN在记忆噪声标签之前会学习更简单的模式。一些研究利用了这一观察结果,并试图在训练的早期阶段将干净的样本从有噪声的样本中分离出来。这种分离方案将数据集划分为一个干净的子集和一个噪声集。在那之后,可以被用于标准监督训练。为了减轻噪声标签的影响,可以用于无相应噪声真实标签的训练。这种训练通常以半监督的方式进行,其中为其中的样本添加伪标签。 我们进行了广泛的实证分析来研究将数据集划分为和子集的有效性。我们发现,的典型结构造成了类别之间的差异或不平衡。图2a(left bars)描述了这样一种情况,当我们使用最近提出的方法时,在噪声CIFAR10(90%噪声率)中包含类不平衡。
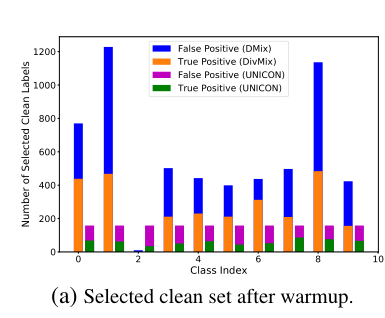
Image 具体来说,我们观察到了从第一类中选择了1228个样本,而第二类只选择了10个样本。然而,真正例(TPs)之间的不平衡尤为重要,因为Dnoisy的伪标签的质量严重依赖于它们。25]等方法试图通过选择更干净的样本来解决这个问题,这反过来增加了假正例或噪声标签计数(图2b(左条)),同时大幅降低了精度。
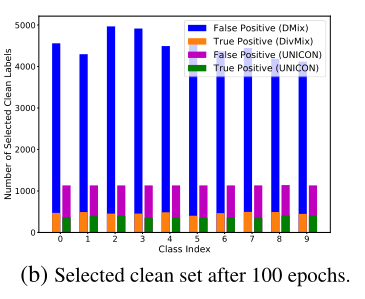
由于所选的clean set 上包含许多假正例,在这一个集合上的监督训练会导致记忆。因此,随后的伪标签召回率大幅下降;如图2c中的伪标签召回所示(左栏)。

Image 这样,选择机制就会对SSL-Training产生负面影响,降低了平均分类精度(2d)
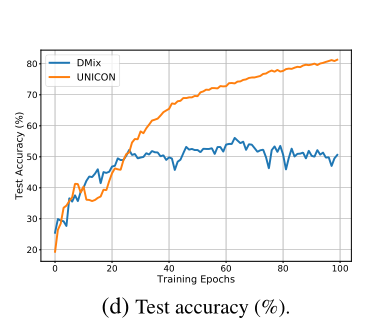
Image 我们建议通过一种简单而有效的均匀选择技术来解决这些问题(图2a(右条))。此外,我们使用对比特征学习来学习更好的无监督特征,而不考虑地面真实或伪标签的质量。我们所提出的方法的细节将在下一节中介绍。
提出的方法
我们提出了一种独特的样本选择方法,并对SSL-Training进行了简单但有效的修改。通过训练,UNICON提高了精度(图2b(右图))和伪标签召回率(图2c(右图))。图2d显示,我们的统一选择和SSL训练的混合框架显著提高了分类性能。接下来,我们在4.1中提出了我们统一的样本选择策略。以及我们在第4.2节中提出的具有对比学习的SSL训练方法。
Uniform Sample Selection
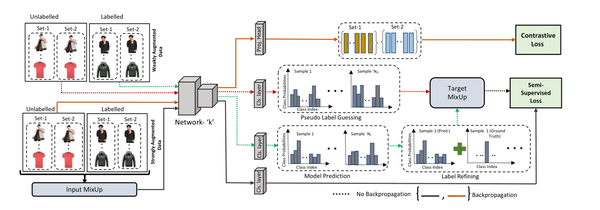
在\mathbb{D}的划分过程中,我们选择通过从每个类中选择/过滤R比例的样本来在Dclean中强制类平衡,其中我们将R定义为过滤率。图3显示了我们提出的选择机制,其中我们将D提供给两个具有相同参数的网络和。
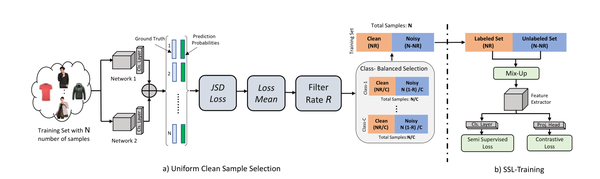
Image 对x_i,,每个网络的平均预测概率可以被表示为 相关的真实标签为 C是总类别数。 为了构造干净、有噪声的子集,我们计算了真实标签和预测概率之间的不一致/散度.JSD定义为
以往的工作使用不同的散度度量来构造干净和有噪声的子集。相比之下,我们选择使用基于JSD的选择,因为它不需要归一化和概率建模。此外,与CE损失不同,JSD在设计上是对称的,其值范围为0到1。 测量散度后,,对于所有的样本,我们计算了一个截止的二次收敛值,可以表示为:
其中,是所有d的均值,是最低散度得分,是滤波系数,是调整阈值。最后,我们决定R是JSD低于的样本的百分比。 这种特殊的设计有两个主要好处。首先,我们根据网络预测分数来确定d_{cutoff}的值(就像JSD取决于预测可能性),这消除了对每个数据集进行手动调优的需求。第二个好处也来自于同样的来源,由预测分数决定。这确保如果网络预测分数始终很低(高),会倾向于一个保守的;这帮助避免在训练的早期阶段进行有噪声的样本选择。 在下一步中,我们将创建特定于类的分区,,其中是类别j的JSD。基于小损失准则[25],我们定义了UNICON选择准则如下:
UNICON Selection Criterion:
对于每个类j,如果差值落在中所有d值的最小R部分内,我们考虑有一个干净的标签。 这里,是j类的样本总数,是属于第j类的第i个图像,其JSD为 最后,根据UNICON的选择标准,我们将每个类中选择的所有干净和有噪声的样本聚合,形成分别具有NR和N(1−R)基数的和。在任何类别的可用样本总数(包括干净的和有噪声的)低于NR/C的情况下,我们对该类别中的所有可用样本进行分析。算法1总结了我们的选择方法。请注意,以前名为Jo-SRC[66]的技术已经使用JSD进行Clean样品检测。然而,我们的样本选择过程与Jo-SRC有显著的不同。例如,[66]中的选择阈值需要在不同的epochs进行手工微调训练,而UNICON自动调整过滤器rate, R,基于网络预测得分;使我们提出了超参数独立的选择方法。
SSL-Training
图3显示了我们的半监督损失和对比损失的ssl训练的细节。
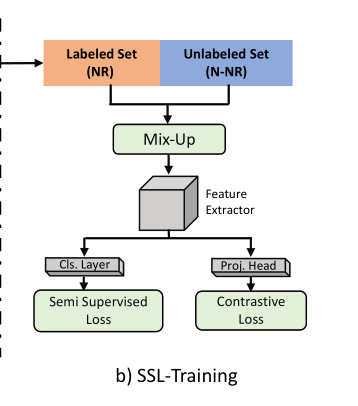
Image 根据FixMatch,我们对的样本进行半监督学习。为此,我们生成了每个样本的两个副本,分别具有弱增强和强增强。伪标签是由弱增广副本生成的,用于计算强增广副本上的半监督损失。我们同样应用了MixUp对和的增强。对于的样本,我们使用从弱增强拷贝得到的伪标签。然而,以这种SSL方式进行的特征或表示学习仍然面临着噪声记忆的风险。在训练过程中,DNN记忆一定部分的噪声样本,无论考虑样本选择技术如何。在干净的子集中存在这样的有噪声的样本,将导致有噪声的SSL训练。为了解决这个问题,我们将对比学习(CL)[6,19]纳入到我们的SSL训练管道中,以促进特征学习,而不依赖于标签/伪标签。这种无监督的虚拟学习方案进一步降低了噪声标签记忆的风险,因为它不依赖于干净和噪声样本的不完全分离,以及在SSL训练过程中产生的错误伪标签。因此,CL的加入提高了我们提出的选择技术的性能,如图4中接收者操作特征曲线(ROC)的曲线下面积(AUC)所示。

Image 在我们的工作中,我们只对未标记集合中的样本使用对比损失。为此,我们使用映射获得的不同增强副本的特征投影和对。对比损失函数[6,19]可以表示为
其中是指标函数,是一个温度常数,B是一个mini-batch的样本数,可以被表示为之间的余弦相似度。我们寻求最小值的loss function是 其中是对比损失函数。对比学习的其他细节以及我们的ssl训练计划的其余部分在补充材料中提供。
实验设置
Datasets
CIFAR10/100:50K training and 10K test images.一般情况下,噪声特性难以控制或确定;例如在自然数据集中的噪声率。因此,合成噪声模型通常用于评价噪声鲁棒算法。在我们的工作中,我们采用了两种类型的噪声模型:对称和非对称。对于对称噪声模型,来自一个特定类的r部分样本均匀分布到所有其他类。另一方面,非对称标签噪声的设计遵循了CIFAR10中发生的真实错误的结构“Truck→ Automobile, Bird → Airplane, Deer → Horse,Cat → Dog”。对于CIFAR100,我们对超类中的每个类使用标签翻转到下一个类。 Tiny-ImageNet:在类数和图像分辨率方面,该数据集是原始ImageNet的一个较小版本。总共有200个类,每个类包含500张图片。 The image size is 64 × 64. Clothing1M:是一个带有噪声标签的大规模真实世界数据集。它包含了来自14个不同的与布相关的类的1M幅图像。由于标签是由卖家提供的图像周围文本制作的,大部分令人困惑的类别(如针织服和毛衣)被错误地标记了。 Webvision :该数据集包含240万张图像(从Flickr和谷歌获得),这些图像被分为与ImageNet ILSVRC12相同的1000个类。根据之前的研究,我们使用谷歌图像子集的前50类作为训练数据。
训练细节
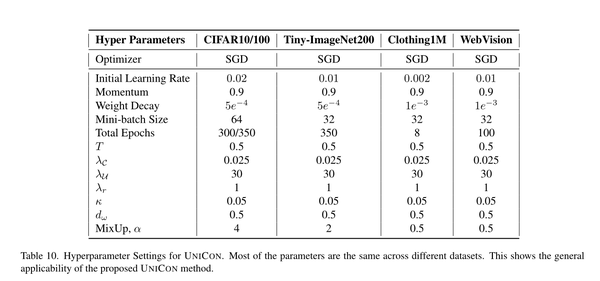
我们为CIFAR10、CIFAR100和Tiny-ImageNet使用PreAct ResNet18架构。对于Clothing1M和WebVison数据集,我们采用一个在ImageNet上预训练的ResNet50网络和一个从头开始训练的搜索ResNetV2网络。我们用一个projection head来修改这些体系结构,它会产生一个大小为128的嵌入向量,以促进对比学习。对于CIFAR-10和CIFAR-100,使用随机梯度下降(SGD)优化器进行优化,优化设置如下:初始学习率(LR)为0.02,权重衰减为5e−4,动量值为0.9,batch size大小为64。对于CIFAR-10和CIFAR-100,我们对每个网络进行大约300个epoch的训练,同时每120个epoch线性衰减learning rate0.1。在之后,在开始选择和ssl训练之前,采用了10个和30个阶段的热身期。对于Tiny-ImageNet,我们使用的初始LR为0.01,权重衰减为1e−3,batch大小为32。我们对网络进行了350个周期的训练,lr-衰减率为0.1/100个epoch。热身期是15个epoch。对于clothing1M,我们选择的初始LR为0.002,重量衰减为1e−3.我们使用相同的设置作为小图像网络的网络视觉。训练周期的总数为100个,lr-衰减率为0.1/40个周期。 对于数据增强,我们遵循[7]中描述的自动增强策略。对于CIFAR-10和CIFAR100,我们使用CIFAR10策略,并将Image-Net策略应用于Tiny-ImageNet。由于这些策略可以从一个数据集转移到另一个数据集,因此ImageNet-policy被用于Clothing1M和Webvision 。
实验结果
我们展示了UNICONN在不同标签噪声场景下的性能。我们从合成的噪声标签数据集(例如CIFAR10,CIFAR100和Tiny ImageNet)开始,然后转移到真实世界的噪声数据集(例如WebVision,Clothing1M).在实验中,我们考虑对称噪声率为20%、50%、80%和90%,非对称噪声率为10%、30%和40%。
- 对称噪音(symmetric/uniform noise):所有的样本,都以同样的概率会错标成其他标签;
- 非对称噪音(asymmetric/class-confitional noise):不同类别的样本,其错标的概率也不相同。
CIFAR10 and CIFAR100 datasets:
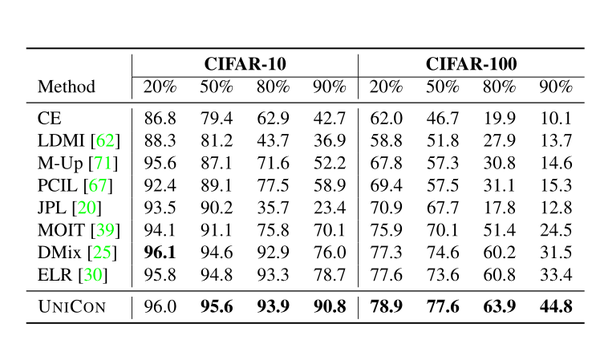
Image 在CIFAR10中,从中度到重度标签噪声,UNICON的表现始终优于baseline。对于90%的噪声率,我们实现了比最先进的技术显著更好的性能改进。对于高噪声率,像[25]这样的技术通常会由于大量假正(FP)而失败。然而,对于低噪声率(20%),[25]的表现略好于我们的。低噪声率表明有更多的干净样本可用于监督学习。一种可能的解释是,缺乏未标记数据(即 Dnoisy < Dclean)使得对比特征学习的效率降低。我们还在非对称噪声的情况下进行了实验。在非对称噪声的情况下,每类受标签噪声的影响不相同。这使得选择干净的样本更具挑战性.然而,UNICON获得了与对称噪声相似的性能增益,如表3所示。
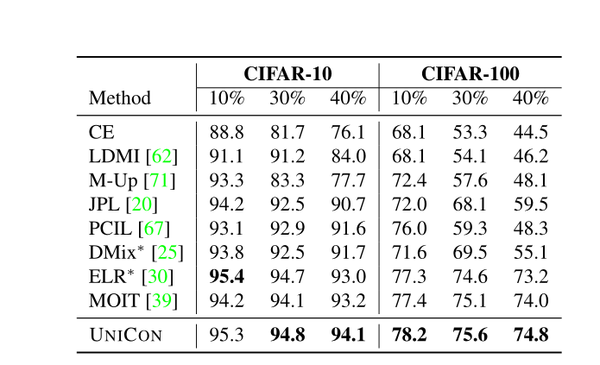
Image 请注意,在10%的噪声率时有一个例外,[30]比UNICON高0.1%。表2和表3包含了CIFAR100数据集的平均测试精度。UNICON在CIFAR100中对标签噪声显示出类似的有效性,在90%的噪声率下,精度提高了11.4%。这种改进在不同的噪声设置下是一致的。虽然ELR[30]、DMix[25]和MOIT[39]在低噪声率下对噪声标签表现出一定程度的阻力,但在高噪声率下的性能并不一致。此外,我们的方法的近似噪声性能也优于表3中的其他基线方法。 TinyImageNet Dataset:表4给出了UNICON和其他先进方法的性能比较。

Image 即使没有标签噪声,Tiny-ImageNet仍然是一个具有挑战性的基准数据集来处理。在标签噪声的存在下,它变得更具挑战性.其中一种baseline M-correction[1]使用损失校正技术处理噪声标签,而NCT[45]利用两个网络的协作学习。然而,与我们的方法相比,这两种方法都表现不佳。表4显示,在所有噪声率下,UNICON的性能比SOTA提高了约1%。 Clothing1M Dataset:表5给出了对这个真实世界的噪声标记数据集的性能比较。
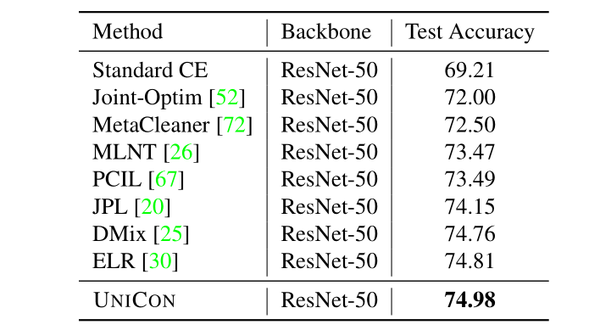
Image 我们比ELR实现了0.17%的性能改进.clothing1M的性能提高有时取决于热身的长度,因为较长时间的CE-based的标准训练可能会导致记忆。在我们的训练中,我们使用了2000步的热身期。 WebVision Dataset:我们在表6中展示了对这个数据集的实验结果。

Image 在验证时,MOIT[39]看到了SOTA的Top-1精度,而我们的方法达到了最好的Top-5精度。与SOTA相比,我们获得了约1.5%的改进(MOIT[39]没有提供前5名的准确性)。此外,UNICON还在ILSVRC12验证集上保护了SOTA的前1名和前5名的准确性。虽然Top-1精度的提高并不显著,但我们在Top-5精度上比DMix[25]提高了1.88%。
Ablation Studies消融实验
在本节中,我们在不同的训练设置下对UNICON进行消融研究。 样品选择性能: 一般来说,干净样本的选择精度直接影响到任何基于选择的噪声标签技术的整体性能。同样,UNICON的成功也取决于其效果如何它可以分离干净的样品。图5a显示了在不同的噪声设置下,我们的选择机制的ROC-AUC评分。可以观察到,无论噪声水平如何,其精度都在稳步上升。

Image 在高噪声率的情况下,网络通常会在干净样本和有噪声样本之间产生混淆。然而,即使在这种情况下,我们的分离方法也被证明是有效的。随着精度的提高,该网络从标记数据中学习到更好的鉴别特征,并能很好地推广到未标记数据。通过生成高质量的伪标签,UNICON显著提高了分类精度(图5b)。
Image Effect of Contrastive Learning:CL是我们框架的关键组件之一。表7显示了CL对我们的方法的整体性能的影响。
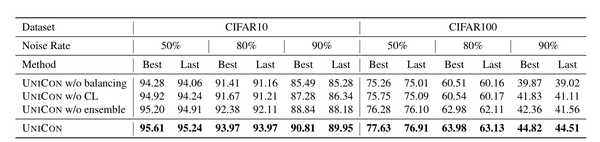
Image 由于CL能够抵抗标签噪声记忆,即使在高标签噪声场景下,它也能显著提高性能。对于CIFAR10和CIFAR100,当噪声率为90%时,没有CL的UNICON的测试精度分别下降了3.53%和2.99%。我们在补充材料中解释了更多关于对比学习及其影响的内容。 Effect of Ensemble and balancing:(集成与平衡的效果:) 在选择过程中,我们取两个网络预测的平均值,而不是仅仅依赖于一个网络。在高噪声率的情况下,这似乎显著提高了性能(见表7)。然而,从两个网络中获取反馈,在训练过程中都存在确认偏差的风险。我们通过一次训练一个网络来防止这种情况的发生。在相同的训练时期,我们在训练另一个网络之前再次执行分离。表7还包含了我们的方法在没有平衡的性能。分类精度的显著下降强调了类别平衡先验的重要性。UNICON对抗记忆的效率如图6所示。

局限性
在这项工作中,为了对抗标签噪声,我们采用了一个类平衡优先。这有助于对抗目前最先进的选择方法造成的人工失衡。在数据集本身表现出极端不平衡的某些极端情况下,这种先验可能是限制性的。然而,在这种情况下,可以根据数据集的类分布相应地更新我们的先验。由于提前了解数据集分布同样具有限制,我们在本研究中不探讨这个方向。此外,尽管我们提供了一个对抗标签噪声的一般解决方案,我们的解决方案在高标签噪声下特别有效。因此,在不包含大量标签噪声的数据集上,有可能超过我们提出的方法。然而,我们强调,这种成功可以归因于优越的训练策略和复杂的设计,而我们的简单解决方案更普遍,即使对于这样的低噪声率的场景,也能提供合理的结果。
结论
在这项工作中,我们提出了UNICON,一个简单而有效的解决方案来对抗标签噪声。我们提出的统一选择技术有效地解决了经常被忽视的基于选择的先进方法的关键的缺点。此外,我们的约束特征学习方法为有噪声标签的通信记忆提供了一个基本的解决方案。有了这两个组件,我们的方法通过减少true positives和CL-based的无监督特征学习之间的类差异,在训练过程中更精确地选择干净的样本。在高精度干净样本上训练的网络为有噪声的标签数据生成更高质量的伪标签,整个过程显著提高了高噪声级的性能。在90%噪声的CIFAR10和CIFAR100上,UNICONN实现了∼10%的性能改进。通过广泛的实证分析,我们证明了我们的方法在不同的噪声场景下的有效性。
补充材料
SSL-Training 细节
在半监督学习(SSL)之前,我们通过uniform selection将训练集分为\mathbb{D}_{clean}和\mathbb{D}_{noisy}。噪声水平为60%的样本训练集图7所示。

Image 我们认为和分别是标记数据和未标记数据。在SSL的开始,我们创建了四组弱增广(WA)数据:

Image 此外,我们还生成了四组强增广(SA)数据:
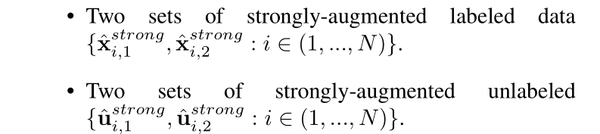
Image 在这里,弱增强被用于标签更新(标签细化和伪标签猜测)。我们使用强增强器来使用反向传播更新网络参数。对于标签细化[25],我们使用网络对弱增广样本x_i的预测来细化给定的标签.对于,输出概率可以写成,
其中N是训练集中的数据点,是网络k对应于的softmax概率。 在得到后,我们如下完善标签: 其中w_i是标签的细化系数,但是,可以从JSD值计算,
其中,是基于样本的JSD调整的标签细化阈值。接下来,我们遵循温度锐化[25]步骤,它给出了我们。类似地,我们通过平均两个网络[25]的预测来计算伪标签。
并应用温度锐化得到q_b。 我们分别将已标记和未标记的图像用其真实标签和伪标签进行聚合。That is,
和
分别为已经标注的集合和未标注的集合。 使用MixMatch有
MixUp[71]提出了一种生成两个输入的凸组合的策略:在这种情况下,来自标记集和未标记集的样本及其对应的真标签和伪标签。
Loss Functions
在采用MixMatch后,半监督损失的计算方法如下
其中,是以y为给定标签的分布p和q之间的交叉熵。 此外,为了防止对所有样本进行单类分配,我们使用基于先验均匀分布的正则化项来对mini-batch中所有样本的正则化输出,类似于Tanaka等人。
这就给出了我们的半监督损失函数,
. 如图8所示

Image 这里,和分别为无监督损失系数和正则化系数。 我们考虑另一个损失函数,对比损失,它只用于中的数据点。设的Projection head 输出对应为和.对比损失函数[6,19]可以定义为
其中是指标函数,是一个温度常数,B是一个mini-batch的样本数,可以被表示为之间的余弦相似度。 对于每个mini-batch,总共有2B个增强的样本,因为我们正在从单个样本中创建一对增强的样本。考虑i和j是一个positive pair.然后将其余的数据点(2B−2)作为否定的例子来处理。我们可以计算所有positive pair的最终对比损失,包括(i,j)和(j,i)在mini-batch中。式不需要标签。由于对比损失不需要标签,它减轻了噪声标签记忆的负面影响。最后,我们累积所有的损失来得到总损失,
其中是对比损失函数。 在算法2中提供了对这些步骤的总结.

Ablation Studies
在本节中,我们将分析UNICON在不同场景下的性能。
不同损失的影响
我们观察到每个损失函数对UNICON性能的贡献。从表8中可以看出,每个损失项都有助于提高性能,而对性能的影响最大。

Image 没有的训练表明我们完全丢弃了所选择的噪声样本。准确率的下降表明了基于伪标签的特征学习的重要意义。提高这些伪标签的质量是UNICON的主要贡献之一
Loss Coefficients
在表9中,我们展示了不同的损失系数的影响。
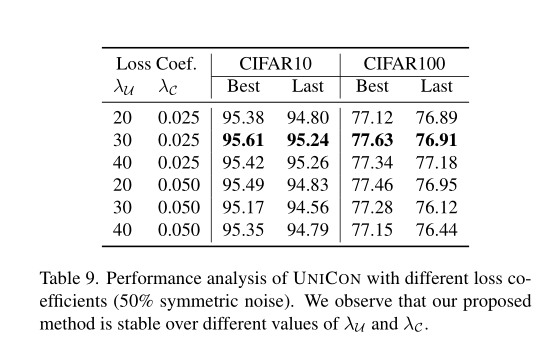
Image 我们观察到UNICON的性能在大范围内保持稳定。我们为\lambda_u和\lambda_c选择了一个30和0.025的值,因为这一组值在CIFAR10和CIFAR100数据集上都具有最佳的性能。我们对所有数据集应用相同的损失系数值,而不考虑类数、样本数、噪声类型、噪声率等。
T-SNE可视化
测试图像特征的t-SNE可视化[55]如图9所示

Image 这些特征是通过在不同的标签噪声设置下训练的模型获得的。我们观察到,随着噪声水平的降低,类分离变得更好。我们进一步注意到,UNICONN在对称的50%噪声下获得了测试图像的最佳分离。然而,当噪声率增加时,学习类分布就变得更具挑战性。9b和9c。此外,我们在图10中比较了我们的方法在存在95%标签噪声的情况下与DMix[25]的性能。
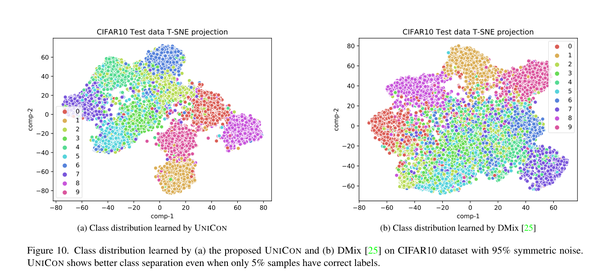
Image 在如此高的噪声率下,分离清洁的样本和有噪声的样本是一项困难的任务。有趣的是,与DMix[25]相比,我们的简单方法有效地学习了更好的类分布。我们将此归因于我们的统一的干净样本选择策略的高精度。
Memorization of Noisy Labels
在标准训练的情况下,网络记忆有噪声的标签,导致泛化性能较差。 然而,我们提出的方法UNICON证明了对标签噪声记忆的抵抗力。我们在图6中展示了这个现象。

Image 我们观察到,通过标准训练,准确性在不同的时期不断提高,这表明了对标签噪声的记忆。与此形成鲜明对比的是,UNICON的训练精度很快饱和,这表明网络在训练后期抵制了对噪声标签的记忆。例如,对于80%对称噪声的理想情况是,如果训练精度为∼的20%,即干净样本的百分比。此外,我们注意到,随着训练数据中标签噪声率的增加,我们的训练能力会恶化。这进一步证实了我们的主张,即UNICON可以有效地对抗记忆标签噪声。
Training Details
超参数设置
WebVision and Clothing1M
对于Clothing1M数据集,首先,我们将图像大小调整为256×256,然后对这些图像进行随机裁剪,得到224×224图像。另一方面,WebVision的每个图像的大小被调整到320×320,并随机使用大小为299×299的裁剪。对于WebVision,我们只考虑了50个类来进行培训和验证。类似地,ILSVRC12验证集只考虑了50个类。WebVision中噪声标签的比例估计在20%左右。结果表明,我们的方法获得的top1精度略低于目前最先进的方法。在某些情况下(低噪声水平),实验结果表明,UNICON表现不如于先进的水平。在WebVision数据集上相对较低的性能可以归因于低标签噪声的存在。
总结
这篇文章使用了DIVIDEMIX的将训练集分为有噪声训练集和无噪声训练集再使用改进的MixMatch进行无监督学习的思想,但是这篇文章采用了与了DIVIDEMIX不同的分离有噪声训练集和无噪声训练集的方法,这种方法解决了DIVIDEMIX的类不平衡问题。此外,为了对抗噪声的记忆效应,在进行SSL训练时在loss上添加了对比学习项。最终的模型如下:
- 作者:VON
- 链接:https://baisihan.asia/article/080ed03a-4365-48bd-af98-9db5715ec1f3
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。